摘要:验证码在网络安全方面发挥着关键作用,验证码的主要目的是区分人类和计算机,用来防止自动化脚本对网站的一些恶意行为。目前绝大多数网站都利用验证码来阻止恶意脚本程序的入侵。验证码经过图像的预处理字符分割,匹配识别等步骤来完成对字符验证的处理,后进过特征提取与匹配等操作完成对一个验证码的识别。本文选取了一个网站进行网站登录的验证码识别,识别结果取得了预期的效果,较好的识别出了验证码。
关键字:验证码;图像识别;Python;预处理
Abstrat:CAPTCHA plays a key role in network security, The main purpose of the CAPTCHA is to differentiate between humans and computers, to prevent some malicious behavior from automating scripts on the site. At present, most websites use Authenticode to prevent the intrusion of malicious script programs. The verification code passes the preprocessing character segmentation of the image, the matching recognition and so on completes the processing to the character verification, the backward feature extraction and the matching operation completes to the verification code recognition. In this paper, a website is selected to identify the verification code, the result obtained the expected results, a better identification of the verification code.
Key words:CAPTCHA; Image recognition; Python; Pretreatment;
0.引言
验证码是目前互联网上一种非常重要非常常见的安全识别技术,先引用一段来自wiki的关于验证码的描述:“全自动区分计算机和人类的公开图灵测试(Completely Automated Public Turing test to tell Computers and Humans Apart,简称CAPTCHA)[1],俗称验证码,是一种区分用户是计算机和人的公共自动程序。在CAPTCHA测试中,作为服务器的计算机会自动生成一个问题由用户来解答。这个问题可以由计算机生成并判定,但是必须有人类才能解答。由于计算机无法解答CAPTCHA的问题,所以回答出问题的用户就可以被认为是人类。”验证码最初是为了防止一些暴力破解的存在,但是后来随着技术的发展,特别是图像识别技术的发展,验证码的识别变的简单,本文介绍了几种常见且普遍的验证码的识别。
常见的验证码有几类,第一种四位数字,随机的一串数字,几乎没有验证作用,第二种是GIF格式的随机数字图片验证码,字符中规中矩,验证效果一般。第三种是PNG格式,随机数字+随机大小写字母,识别难度较大。第四种是JPG格式,随机数字+随机颜色+随机位置+随机长度,难度较大。
1.Python简介
Python是一种粘性语言,其具有良好的简洁性、易读性以及可维护性。本文使用的PIL库是Python的一种图形识别库。
Python是纯粹的自由软件,源代码和解释器CPython遵循GPL(GNU General Public license)协议。Python语法简洁清晰,特色之一是强制用空白符作为语句缩进。
Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。
Python的设计哲学是“优雅”、“明确”、“简单”。因此,Perl语言中“总是有多种方法来做同一件事”的理念在Python开发者中通常是难以忍受的。Python开发者的哲学是“用一种方法,最好是只有一种方法来做一件事”。在设计Python语言时,如果面临多种选择,Python开发者一般会拒绝花俏的语法,而选择明确的没有或者很少有歧义的语法。由于这种设计观念的差异,Python源代码通常被认为比Perl具备更好的可读性,并且能够支撑大规模的软件开发。这些准则被称为Python格言。在Python解释器内运行import this可以获得完整的列表。
2.Tesseract-OCR
Tesseract,一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,与Microsoft Office Document Imaging(MODI)相比,我们可以不断的训练的库,使图像转换文本的能力不断增强;如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。Tesseract算法分为下列几个步骤:
轮廓分析:文本图像中含有许多字符,在OCR识别前,首先需要给每个字符标记有效边界,即:轮廓。它采用了一种嵌套的轮廓搜索算法,不仅搜索轮廓本身,还搜索嵌套轮廓的轮廓。最后将分析所得的轮廓组合成文本块。
文本块被划分:顾名思义将图像划分成若干行,将文本行分割成字符。
特征提取,进行第一次识别,再次识别上次认错的字符,当识别率达到设定的阈值时进行下一步。
语言分析:利用词义、词频、语法规则或语料库等语言先验知识识别结果进行校正,提高识别率。
这个OCR识别技术有着积极的应用场景:银行卡的识别、身份证识别、车牌号码识别等。这些场景具有和文本研究素材很相似的特点:字体单一、字符较为简单的数字或字母组合、文字的排列是标准统一化的,所以在获取原始数据比较规范的情况下,识别起来的难度也是不大的。
3.识别模型
3.1基本模型
验证码识别的模型大致可以分为以下阶段:1)图片收集;2)图片预处理;3)图片字符切割;4)图片尺寸归一化;5)图片特征提取匹配。图1简单描述了整个模型的流程[2]。

3.2图片收集
识别验证码之前,首先需要收集验证码,图2是常见的几种验证码,是从一些网站上获取验证码原图下载下来。这些验证码分为几种, 第一是背景单一,随机四位数字;第二种是背景模糊,灰度值有所变化;第三种是随机颜色,随机位置随机数字;第四种是随机数字,随机字母,随机位置的验证码。这些验证码获取到后要对彩色图像进行灰度转化,然后进行去噪等预处理。

3.3预处理
一般的图像处理的定义是将一个文字图像分拣出来交给识别模块识别,这一过程称为图像预处理。在图像分析中,对输入图像进行特征抽取、分割和匹配前所进行的处理。
预处理的主要目的是消除图像中无关的信息,恢复有用的真是信息,增强有关信息的可检测性和最大限度地简化数据,从而改进特征抽取、图像分割、匹配和识别的可靠性。
针对于上述的原始素材,我们预处理的过程是将彩色图片先转化为灰度化,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。一般常用的是加权平均法来获取每个像素点的灰度值,并且设置相应的阈值来判定图像。然后进行图像二值化,所谓图像的二值化处理就是将图像上的点的灰度值化为0到255的范围,将整个图像呈现出黑白的效果。即将256个灰度等级的灰度图像通过适当的阈值选取而获得仍然可以反映整体和局部特征的二值化图像。
设原始灰度图像为发f(x, y),二值化处理后的图像为g(x, y)则二值化过程可以表示为
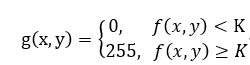
式中f(x, y)是原始图像坐标为(x,y)的点的像素值,g(x,y)是二值化处理后的改点的像素值,0表示黑色,255表示白色。在实际处理中,进行图像二值化处理的关键是要确定合适的阈值,使得字符与背景能够分离出来。

进行二值化后,图像还存在一些噪点,下一步的工作就是清除噪点,我们平常常见的降噪算法一般都是一些滤波算法,这里要用的是均值滤波法,这是一种局部空间域处理的算法。我们假设一副图像f(x,y)为NxN的矩阵,处理后的图像为g(x,y),它的每个像素的灰度级由包含(x,y)邻域的几个像素的灰度的平均值所决定,可以用下面的公式处理后得到图像。
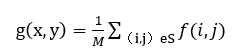
式中x,y=0,1,2……,N-1;s是以(x,y)点为中心的邻域的集合,M是s内坐标总数。图像邻域,这种算法的处理效果与所用的邻域半径有关。半径越大,则图像模糊程度也越大。
为了减少模糊程度,我们把邻域选为8。如下图所示,
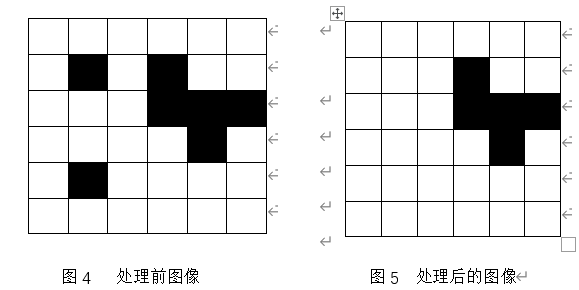
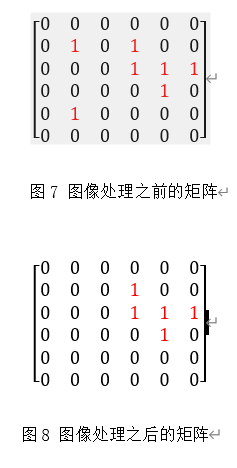
采用矩阵表示如下,假设转化后的二值化图像中,白色部分用0表示,黑色部分有1表示,对于噪音点,我们判断该点和相邻的几个像素点的差异性。这些像素点按照位置不同,还可以分成三类1)顶点A;2)非顶点的边界点B;3)内部点C。种类如下图所示。
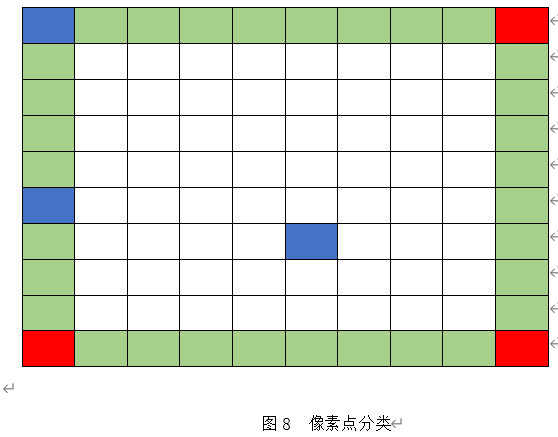
1):A类点需要计算周边及相邻的3个点。
2):B类点需要计算周边及相邻的5个点。
3):C类点需要计算周边及相邻的8个点。
经过我们处理后可以去除大部分噪声。
3.4字符切割
图像的字符分割是在上一步图像二值化后的下一个步骤,是将验证码图像中的字符单独分离出来。字符切割的目的是为下一步字符匹配识别等做准备。这里采用的是上下轮廓投影法相结合的方法。其原理:首先利用水平、竖直投影法找到二值化后的的验证码图像中字符的边界,确定边界后,再进行图像阈值分割。[3] 图像阈值分割是一种广泛应用的分割技术,其特点是操作简单,分割结果是一系列连续区域。灰度图像的阈值分割一般基于如下假设:图像目标或背景内部的相邻像素间的灰度值是高度相关的,目标与背景之间的边界两侧像素的灰度值差别很大,图像目标与背景的灰度分布都是单峰的。如要图像目标与背景对应的两个单峰大小接近、方差较小且均值相差较大,则该图像的直方图具有双峰性质[4]。阈值化常可以有效分割具有双峰性质的图像。

3.5图片尺寸归一化
在进行图像切割后,得到了原来图像的几个单个的图片,但是由于我们是根据原图边缘切割的,切割出来的图像有大有小,需要我们对这些图像进行尺寸的归一化,便于后期对图片的识别。[5]
3.6图片特征提取匹配
以形状特征检索图像目标效果都是非常理想的,当前对其的研究主要体现在以下几方面;第一,基于形状特征实现检索,虽然理论上说得通,但是实践上还缺少较为系统的数学模型作为支撑;第二,当检索目标出现变化时,检索的结果并不是很理想;第三,大部分的形状特征,只是对检索目标局部性质的体现,仍无法区分出检索目标的综合属性,且要增加计算时间等。[6]
常用的特征提取方法包括两种:即通过图像分割,对目标、颜色区域等进行有效的划分,以此为基础构建索引。还有一种将图像划分,针对于不同划分区域进行特征提取,最后构建索引。
尺度不变特征转换,是常用的一种图像特征提取方法,其算法的步骤主要包括以下几点:一是对尺度空间进行构建,对极值点进行检测,继而得到其尺度不变性属性;二是对于特征点进行有效过滤,然后通过高效的定位,对不稳定的特征点进行排除;三是获取特征点的描述符,并在其基础上进行方向值的分配;四是获取特征描述子,然后在描述符的基础上找出匹配点。其中描述子的获取方法主要为在特征点的基础上,将16*16的领域,当作是采用窗口,然后将采样点、特征点组成的相对空间,利用高斯加权,然后将其纳入到8个bin的直方图,最终获得描述子。
本文采用模板匹配法,先提取样本的n维特征,在提取待识别字符的n维特征,对照产生结论。算法采用欧式距离。即经过计算待识别字符的特征向量与模板库中提取的特征向量之间的欧式距离,取模板中与计算出的欧式距离最小的作匹配,将匹配字符输出。
4.实验及结果
本论文实验验证的环境是Python环境,需要导入PIL(Python Imagine Library)图像处理库,其功能非常强大。
4.1 字符验证码的识别
本论文中选取的实验对象的验证码是从网络上选取下载下来的,是

现在比较流行的几种验证码,比较简单的是随机数字,背景、颜色单一的验证码,比较复杂的是随机数字+随机位置+随机颜色+随机字母的验证码,本论文中使用Python都对其进行了识别,识别结果如下:

我们可以看到,4张验证码中有3张是可以正确识别的,对最后一张的随机数字+随机位置+随机颜色+随机字母的验证码识别率较低。
4.2应用场景检测
本实验访问了全国道路货运车辆公共监管与服务平台,轻易的拿到了验证码地址。通过地址下载验证码图片资源进行识别。获取到的验证码如下图,


识别情况如下:

本次实验中,20组中有3组识别错误,在此次验证码样
本实验中,正确率为85%。能够识别大部分验证码。
4.3文字识别检测
获取文本信息如下:
.jpg)
.jpg)


识别结果如下:

本次实验中,大部分字符都能识别,个别相似的字符出现识别错误或者不能识别的情形。
5.总结
本论文探讨了目前识别验证码的常见方法及步骤,从最初的获取图片素材到预处理,图片的切割、匹配识别等。介绍了目前比较流行的识别方法,从实验结果来看,可以识别大部分的字符验证码和文字等。
另外,本论文也存在许多不足之处,本论文实验中收集的验证码比较单一,字符较为简单,背景单一,较为容易识别。
参考文献
[1].吕霁.浅谈验证码的识别[J].河北能源职业技术学院学报,2015,(57):72-74.
[2].杨雄.基于Python语言和支持向量机的字符验证码识别[J].数字技术与应用2017,(04):72-74.
[3].汪洋,许映秋,彭艳兵.基于KNN技术的校内网验证码识别.计算机与现代化,2017(02)
[4].张芮,陈萱玮,李桐.浅谈Android平台下OCR研究与实现.工业设计,2015,(4):94-95
[5].李霄霄.基于OCR的字符识别的研究与实现.科技视界,2017(14):98-98
[6].杨小军.图片特征提取.中小企业管理与科技,2017,(03):106-107
附录
附录一:Python中库函数代码
#!/usr/bin/env python
try:
import Image
except ImportError:
from PIL import Image
import os
import sys
import subprocess
from pkgutil import find_loader
import tempfile
import shlex
from glob import iglob
from distutils.version import LooseVersion
numpy_installed = find_loader('numpy') is not None
if numpy_installed:
from numpy import ndarray
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
tesseract_cmd = 'tesseract'
tesseract_cmd='C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
RGB_MODE = 'RGB'
OSD_KEYS = {
'Page number': ('page_num', int),
'Orientation in degrees': ('orientation', int),
'Rotate': ('rotate', int),
'Orientation confidence': ('orientation_conf', float),
'Script': ('script', str),
'Script confidence': ('script_conf', float)
}
class Output:
STRING = "string"
BYTES = "bytes"
DICT = "dict"
class TesseractError(Exception):
def __init__(self, status, message):
self.status = status
self.message = message
self.args = (status, message)
class TesseractNotFoundError(OSError):
def __init__(self):
super(TesseractNotFoundError, self).__init__(
tesseract_cmd + " is not installed or it's not in your path"
)
class TSVNotSupported(Exception):
def __init__(self):
super(TSVNotSupported, self).__init__(
'tsv output not supported. It requires Tesseract >= 3.05'
)
def run_once(func):
def wrapper(*args, **kwargs):
if wrapper._result is wrapper:
wrapper._result = func(*args, **kwargs)
return wrapper._result
wrapper._result = wrapper
return wrapper
def get_errors(error_string):
return u' '.join(
line for line in error_string.decode('utf-8').splitlines()
).strip()
def cleanup(temp_name):
''' Tries to remove files by filename wildcard path. '''
for filename in iglob(temp_name + '*' if temp_name else temp_name):
try:
os.remove(filename)
except OSError:
pass
def prepare(image):
if isinstance(image, Image.Image):
return image
if numpy_installed and isinstance(image, ndarray):
return Image.fromarray(image)
raise TypeError('Unsupported image object')
def save_image(image):
image = prepare(image)
img_extension = image.format
if image.format not in {'JPEG', 'PNG', 'TIFF', 'BMP', 'GIF'}:
img_extension = 'PNG'
if not image.mode.startswith(RGB_MODE):
image = image.convert(RGB_MODE)
if 'A' in image.getbands():
# discard and replace the alpha channel with white background
background = Image.new(RGB_MODE, image.size, (255, 255, 255))
background.paste(image, (0, 0), image)
image = background
temp_name = tempfile.mktemp(prefix='tess_')
input_file_name = temp_name + os.extsep + img_extension
image.save(input_file_name, format=img_extension, **image.info)
return temp_name, input_file_name
def subprocess_args(include_stdout=True):
# See https://github.com/pyinstaller/pyinstaller/wiki/Recipe-subprocess
# for reference and comments.
kwargs = {
'stdin': subprocess.PIPE,
'stderr': subprocess.PIPE,
'startupinfo': None,
'env': None
}
if hasattr(subprocess, 'STARTUPINFO'):
kwargs['startupinfo'] = subprocess.STARTUPINFO()
kwargs['startupinfo'].dwFlags |= subprocess.STARTF_USESHOWWINDOW
kwargs['env'] = os.environ
if include_stdout:
kwargs['stdout'] = subprocess.PIPE
return kwargs
def run_tesseract(input_filename,
output_filename_base,
extension,
lang,
config='',
nice=0):
command = []
if not sys.platform.startswith('win32') and nice != 0:
command += ('nice', '-n', str(nice))
command += (tesseract_cmd, input_filename, output_filename_base)
if lang is not None:
command += ('-l', lang)
command += shlex.split(config)
if extension != 'box':
command.append(extension)
proc = subprocess.Popen(command, **subprocess_args())
status_code, error_string = proc.wait(), proc.stderr.read()
proc.stderr.close()
if status_code:
raise TesseractError(status_code, get_errors(error_string))
return True
def run_and_get_output(image,
extension,
lang=None,
config='',
nice=None,
return_bytes=False):
temp_name, input_filename = '', ''
try:
temp_name, input_filename = save_image(image)
kwargs = {
'input_filename': input_filename,
'output_filename_base': temp_name + '_out',
'extension': extension,
'lang': lang,
'config': config,
'nice': nice
}
try:
run_tesseract(**kwargs)
filename = kwargs['output_filename_base'] + os.extsep + extension
with open(filename, 'rb') as output_file:
if return_bytes:
return output_file.read()
return output_file.read().decode('utf-8').strip()
except OSError:
raise TesseractNotFoundError()
finally:
cleanup(temp_name)
def file_to_dict(tsv, cell_delimiter, str_col_idx):
result = {}
rows = [row.split(cell_delimiter) for row in tsv.split('\n')]
if not rows:
return result
header = rows.pop(0)
if len(rows[-1]) < len(header):
# Fixes bug that occurs when last text string in TSV is null, and
# last row is missing a final cell in TSV file
rows[-1].append('')
if str_col_idx < 0:
str_col_idx += len(header)
for i, head in enumerate(header):
result[head] = [
int(row[i]) if i != str_col_idx else row[i] for row in rows
]
return result
def is_valid(val, _type):
if _type is int:
return val.isdigit()
if _type is float:
try:
float(val)
return True
except ValueError:
return False
return True
def osd_to_dict(osd):
return {
OSD_KEYS[kv[0]][0]: OSD_KEYS[kv[0]][1](kv[1]) for kv in (
line.split(': ') for line in osd.split('\n')
) if len(kv) == 2 and is_valid(kv[1], OSD_KEYS[kv[0]][1])
}
@run_once
def get_tesseract_version():
'''
Returns a string containing the Tesseract version.
'''
try:
return LooseVersion(
subprocess.check_output(
[tesseract_cmd, '--version'], stderr=subprocess.STDOUT
).decode('utf-8').split()[1]
)
except OSError:
raise TesseractNotFoundError()
def image_to_string(image,
lang=None,
config='',
nice=0,
boxes=False,
output_type=Output.STRING):
'''
Returns the result of a Tesseract OCR run on the provided image to string
'''
if boxes:
# Added for backwards compatibility
print('\nWarning: Argument \'boxes\' is deprecated and will be removed'
' in future versions. Use function image_to_boxes instead.\n')
return image_to_boxes(image, lang, config, nice, output_type)
if output_type == Output.DICT:
return {'text': run_and_get_output(image, 'txt', lang, config, nice)}
elif output_type == Output.BYTES:
return run_and_get_output(image, 'txt', lang, config, nice, True)
return run_and_get_output(image, 'txt', lang, config, nice)
def image_to_boxes(image,
lang=None,
config='',
nice=0,
output_type=Output.STRING):
'''
Returns string containing recognized characters and their box boundaries
'''
config += ' batch.nochop makebox'
if output_type == Output.DICT:
box_header = 'char left bottom right top page\n'
return file_to_dict(
box_header + run_and_get_output(
image, 'box', lang, config, nice), ' ', 0)
elif output_type == Output.BYTES:
return run_and_get_output(image, 'box', lang, config, nice, True)
return run_and_get_output(image, 'box', lang, config, nice)
def image_to_data(image,
lang=None,
config='',
nice=0,
output_type=Output.STRING):
'''
Returns string containing box boundaries, confidences,
and other information. Requires Tesseract 3.05+
'''
# TODO: we can use decoration for this check
if get_tesseract_version() < '3.05':
raise TSVNotSupported()
if output_type == Output.DICT:
return file_to_dict(
run_and_get_output(image, 'tsv', lang, config, nice), '\t', -1)
elif output_type == Output.BYTES:
return run_and_get_output(image, 'tsv', lang, config, nice, True)
return run_and_get_output(image, 'tsv', lang, config, nice)
def image_to_osd(image,
lang=None,
config='',
nice=0,
output_type=Output.STRING):
Returns string containing the orientation and script detection (OSD)
'''
config += ' --psm 0'
if output_type == Output.DICT:
return osd_to_dict(
run_and_get_output(image, 'osd', lang, config, nice))
elif output_type == Output.BYTES:
return run_and_get_output(image, 'osd', lang, config, nice, True)
return run_and_get_output(image, 'osd', lang, config, nice)
def main():
if len(sys.argv) == 2:
filename, lang = sys.argv[1], None
elif len(sys.argv) == 4 and sys.argv[1] == '-l':
filename, lang = sys.argv[3], sys.argv[2]
else:
sys.stderr.write('Usage: python pytesseract.py [-l lang] input_file\n')
exit(2)
try:
print(image_to_string(Image.open(filename), lang=lang))
except IOError:
sys.stderr.write('ERROR: Could not open file "%s"\n' % filename)
exit(1)
if __name__ == '__main__':
main()