0.前言
消除重复数据分为几种不同的情况,请参考食用
1.使用DISTINCT 关键字。
适用场景:返回的数据有重复的行时,会直接消除掉所有重复的行数据。
例如: 下面这个表,
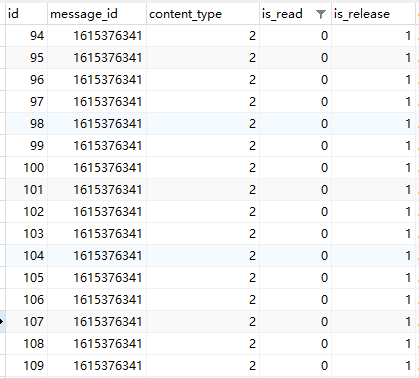
如果我们执行下面的操作
SELECT DISTINCT message_id FROM message_receive返回结果如下:
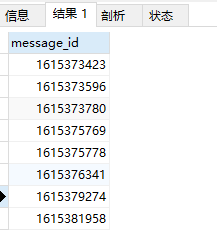
可以看出,返回的数据没有任何一个重复的行。我们继续操作,执行下面的语句
SELECT DISTINCT message_id,content_type FROM message_receive这次我们查询了两个字段,返回结果如下:
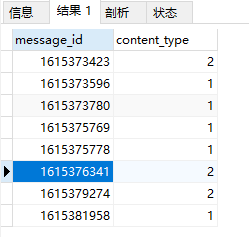
可以看出,没有任何一行是完全一样的。
2.HAVING COUNT 关键字
COUNT(*) 函数返回在给定的选择中被选的行数。配合HAVING 关键字一同使用。
适用场景:可以用来对结果中某一个字段的唯一性进行筛选,而不管其他字段。
例如:
现在要查两个字段,在数据库中字段都是多对多的关系。当我们确定一个一个字段时,就可以利用这个来进行筛选。
select user_id,user_account,name,is_read,message_id
FROM user,message_receive
WHERE message_id = 1615373423
GROUP BY user_account
HAVING count(user_account)=1
上面这段sql表示从两个表中查找数据,对于返回的数据使用
GROUP BY ****
HAVING count(*****)=1
来进行筛选,表示(字段)的数量 (大于等于)数值。 符合这样的数据返回。
注意,如果你写 HAVING count(****)=10。 表示查找某个字段出现10次的数据,返回的整体数据仍然是一条,而不会出现一条。