向量空间模型(Vector Space Model)是将文本转换为向量的代数模型,主要用于自然语言处理、文本分析等领域。目前,向量空间模型广泛适用于各个领域,它是将文本直接转换为数学问题的最直接方式。
1.词袋模型
词袋模型(Bag of Words Model)是一种基于广泛应用于自然语言处理和信息检索的词语模型。之所以称为“词袋”是因为其形象地将若干词语放到一个“袋子”中,而不考虑词语之间的语法及词语之间的相互顺序。
例如,A、B两个示例文件见表
| 文件 | 词语 |
| 文件A | 小张 喜欢 打 篮球 和 打 羽毛球 |
| 文件B | 小李 喜欢 打 羽毛球 |
将上表中词语进行混合得到“小张、喜欢、打、篮球、和、羽毛球、小李”,得到的混合词汇即可称作词袋,每个文件中的词语内容都是词袋中词语的组合。因此,可以利用词语的向量来表示两个文件,向量的大小是词语在文件中的词频,对示例文件分词并计算词频形成向量,见下表。
| 文件 | 词语 |
| 文件A | 小张(1) 喜欢(1) 打(2) 篮球(1) 和(1) 羽毛球(1) 小李(0) |
| 文件B | 小张(0) 喜欢(1) 打(1) 篮球(0) 和(0) 羽毛球(1) 小李(1) |
精简后的文件A可以用向量表示为“1121110”,文件B可以用向量表示为“011011”,基于向量可以进行其他进一步操作。
词袋模型非常简单易于理解,但是也是这种语法和词序无关的词袋理论假设,不太符合自然语言文字的实际分布规则和含义,导致它不能进行更深层次精准的自然语言处理。因此,它擅长的是与词频相关、忽略词序和语法的文本信息处理。词袋模型也可应用到文本分类中。在基于贝叶斯的垃圾邮件过滤中,一封邮件被看作若干无序词汇的集合,这些词汇命中两种概率中的一种:一种是属于垃圾邮件的概率;另一种是属于正常邮件的概率。
2.TF-IDF算法
向量空间模型是很多算法应用的理论基础,其中一个典型的应用是在一推文件中选择属于每个文件最具有代表性的词汇,该算法的名称为 TF-IDF(Term Frequency-InverseDocument Frequency),它是一种常用于检索系统的加权技术。
TF-IDF是向量空间模型的典型体现,其原理也相对比较简单,它的核心思想是:文件中每个词的重要性与它在当前文件中出现的次数成正比,但是与它在其他文件中出现的次数成反比。
例如,如果只有文件A中出现的某词语,其他文件中均不存在该词语,且该词语在文件A中出现的频率也相对较高,则认为这个词语的权值在文件A中相对较大,对文件A具有一定的代表性;但若该词语不仅文件A中有,其他文件中几乎也有出现,即使该词语在文件A中的频率也较高,但是它的权值也会相对减小。进一步推论,倘若一个词语在某一文件中出现的频率很高,并且在其他文件集合中出现的频率很低,那么则认为该词语对文A有一定的代表性,能够通过该词与其他文件形成较好的内容区分能力。
用数学公式表达TF-IDF中的TF(Term Frequency,词频),如下所示:
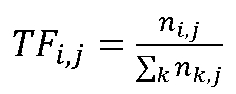
其中,nij是指该词在文件dj中出现的次数,分母表示在文件dj中所有字词的出现次数之和,简单地理解即为该词在此文件中出现的频率。
而对于IDF(Inverse Document Frequency,逆向文件频率),用数学公式表达如下所示:
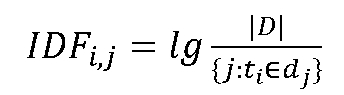
其中,|DI为资料中所有文件的总数;分母表示包含词语t的文件数目。最终第i个文件中的第j个词的TF-IDF权值为TF1xIDFj。
结合上述TF及IDF的数学公式,TF-IDF的计算值即为TF与IDF的积。例如,给定如下表所示三个文件,计算词语“奋斗”的TF-IDF值。其中,文件内容已经按照空格符分词处理。
| 文件 | 文件中对应词语集合 |
| A | 努力 向前 奋斗 奋斗 使得 未来 更好 |
| B | 创新 创新 万众 智慧 |
| C | 奋斗 是 人生 的 一 部分 |
1)计算TF。文件A中只有一个“奋斗”,但是共有词组4个,所以TF=2/7≈0.2857。
(2)计算IDF。词汇“奋斗”在文件A和文件C中出现过,一共有三个文件,所以IDF=1g(3/2)。
(3)计算TF-IDF。将TF和IDF相乘,TF-IDF=TFxIDF=0.2857x1g(3/2)≈0.05。因此“奋斗”在文档A中的权值为0.05。
TF-IDF 算法并不是一个完美的权值计算方式,因为它的实现是基于“对区别文件中最有意义的词语应该是那些在文件中出现频率高,而在整个文件集合的其他文件中出现频率较低的词语”的假设条件,目的是突出重要词语,抑制次要词语。
它需要通过不断训练进行分析,不仅如此,对于段文本的处理也会成为它的弊端。因
此,TF-IDF算法在长文本中效果会比较好,但是对于短文本相对而言效果会略差。相似的算法还有TextRank算法,该算法是一种基于文本表达顺序和频率的权重计算方式,主要用于短文本中的权重分析。
TF-IDF 算法是向量空间模型的典型应用,TF-IDF算法权重计算方法还经常会与余弦相似性算法一同使用在向量空间模型中,如用于判断两个不同文件之间的相似性。
向量空间模型的缺陷如下。
(1)不适合太长的文件。文件太长则向量过大,会影响计算的结果。
(2)忽视了文本中语义和语法的表达。例如,同样两个词语在文件中的顺序不同,则可能表达的含义也不尽相同,而在向量空间模型中忽略了其中的作用。
(3)词语之间的必须完全出现进行匹配,相似词语或者词语的子词语没有进行有效的匹配。例如,“珠穆朗玛峰”和“珠峰”实际表达的是同一信息,“踢足球”和“踢球”也有很高的相似度。
在基本的向量空间模型基础之上,还扩展了不少向量空间模型,如广义向量空间模型、基于主题的向量空间模型等。相对于向量空间模型,还存在标准布尔模型(Standard BooleanModel)等。