余弦相似性算法是基于向量空间模型的算法,其关键词的向量依赖于TF-IDF算法或其他关键词提取算法。
1.原理
余弦相似性顾名思义是指通过余弦的方式计算相似度。余弦是两个向量的夹角,因此可将需要进行相似性比较的内容视为余弦的两个向量,若两个向量大小、方向完全重合,则夹角为0°,余弦值为1;同理,两个向量完全相反,即夹角为180°,余弦值为-1,如图所示。因此,余弦相似性是基于向量的算法,并利用两个向量方向和大小的不同,将此种转换为余弦值,并将余弦值用作衡量信息的差异的标准。
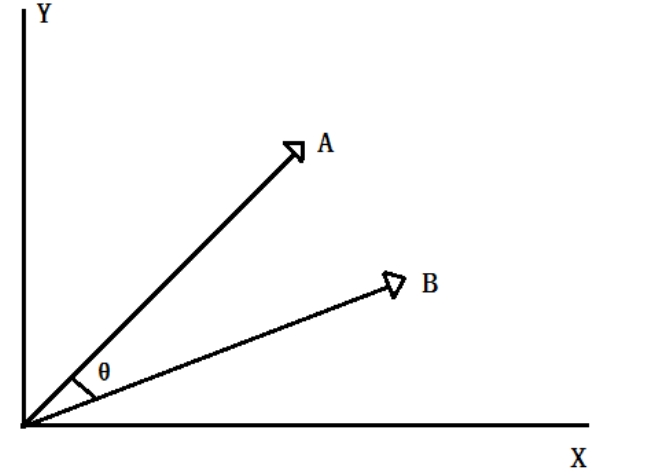
此处的余弦值大小即可表达处两个向量之间的相似度,这也是余弦相似性算法能够进行相似度计算的基本原理,余弦相似性常常用于文本内容比较。
2.公式解析
计算向量的a(x1,y1)和向量b(x2,y2)的余弦值,可采用如下公式:
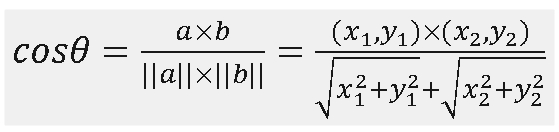
上述公式是针对二维向量的计算,在实际工作中,很可能是n维向量的计算,计算公式如下所示:
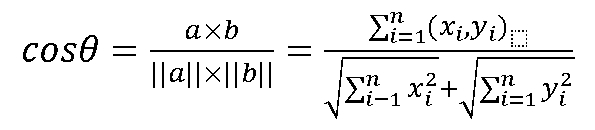
3.计算网页文本相似过程
采用余弦相似度进行相似度分析,可以参考下表中的内容,该示例通过余弦相似性计算文本之间的相似程度。
| 文本编号 | 文本内容 |
| 文本A | 数据价值是一种数据艺术 |
| 文本B | 算法价值是一种算法艺术 |
由于文本的相似性在于文本的词语之间的相似性,所以可以将词语在文本中出现的
率初步作为词语在文本中的权重。
(1)分词处理。将文本A和文本B进行分词处理,文本4分词后结果为“数据价值是一种 数据 艺术”;文本B分词后结果为“算法 价值是一种 算法 艺术”。在实际工程中可利用TF-IDF算法或者TextRank算法等提取关键词,而不仅限于对分词的处理。
(2)向量集。根据上述的分词结果,将所有词语进行合并,出现的相同词语仅记一次,获得向量集“数据 算法 价值 是一种 艺术”。
(3)词频计算。针对文本A和文本B得到的公共向量集“数据 算法 价值是一种艺术”,将文本A和文本B计算词频,存在则记录词频,不存在则即为0。对于文本A可计算词频“数据(2)算法(0)价值(1)是(1)一种(1)艺术(1)”;对于文本B可计算词频“数据(0)算法(2)价值(1)是(1)一种(1)艺术(1)”。
(4)形成特征向量。根据特征集计算的词频信息,将词频转换为特征向量,特征向量以特征集为基础,词频为特征集对应词语的权重。针对文本A特征向量为“201111”,文本B的特征向量为“021111”。
(5)相似度计算。已经获得特征向量{2,0,1,1,1,1}和{0,2,1,1,1,1},将问题转换为对向量求夹角。根据余弦夹角公式,计算过程如下所示:
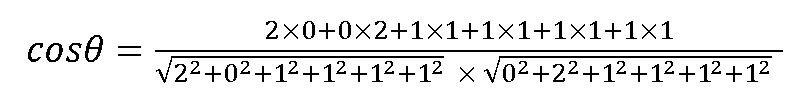
通过上述过程,最终计算出余弦值为0.5,因此可认为文本“数据价值是一种数据艺术”与“算法价值是一种算法艺术”的文本相似度为0.5。